

MisoTTS: Open-Weights Ultra-Fast Voice Synthesis Model Unveiled
Start-up Miso Labs has just unveiled MisoTTS, an 8-billion-parameter text-to-speech (TTS) model released under "open weights" licensing. Designed to generate highly expressive and realistic voices, this model stands out for its ability to adapt not only to written text but also to the tone of a speaker by integrating audio context.
Combating the "Uncanny Valley" Effect
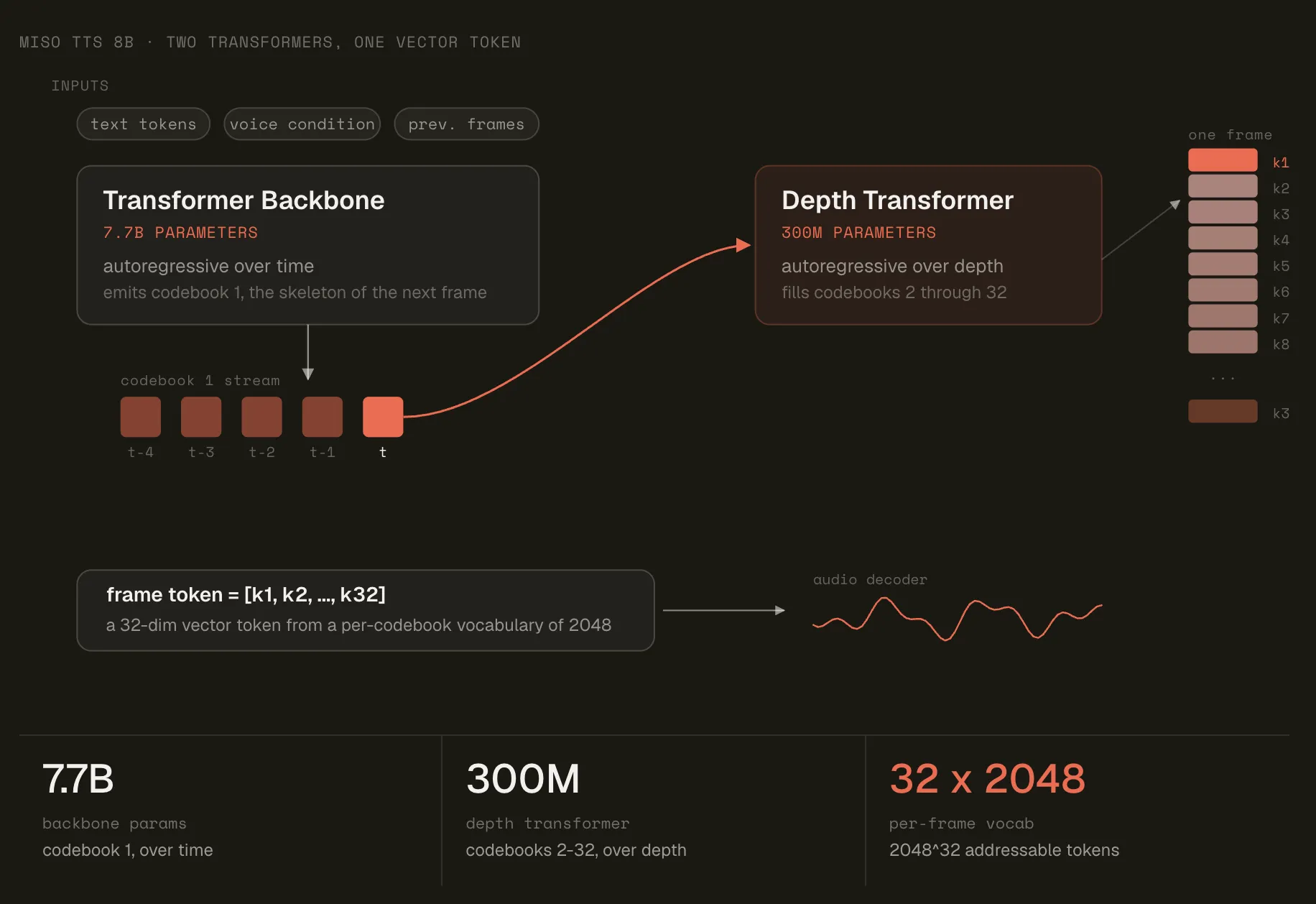
To overcome the limitations of traditional models that often lack naturalness, MisoTTS leverages a Transformer RVQ (Residual Vector Quantization) architecture, inspired by Sesame CSM. It combines a Llama 3.2-style main network with a lighter audio decoder using the Mimi tokenizer.
Unlike conventional systems that rely solely on text, MisoTTS can analyze prior audio context. This dual-input capability allows it to adjust intonation, rhythm, and emotional tone in responses based on the user’s voice, avoiding the robotic and impersonal delivery often associated with synthetic speech.
Residual Vector Quantization for Latency Optimization
The standout feature of MisoTTS lies in its use of Residual Vector Quantization (RVQ). Traditionally, expanding a model’s audio vocabulary to capture the nuances of human speech requires significantly increasing the number of parameters. MisoTTS solves this by emitting a vector of multiple indices (32 code dictionaries) instead of a single token. This enables it to achieve an enormous virtual vocabulary without adding computational overhead.
In terms of performance, Miso Labs reports a record-breaking inference latency of just 110 ms (default execution in torch.bfloat16). For context, the start-up positions its model far ahead of ElevenLabs (700 ms) and Sesame (300 ms).
Source: MarkTechPost. Editorial synthesis assisted by AI — TechnoExpress.