

OpenAI’s new method predicts AI risks before release
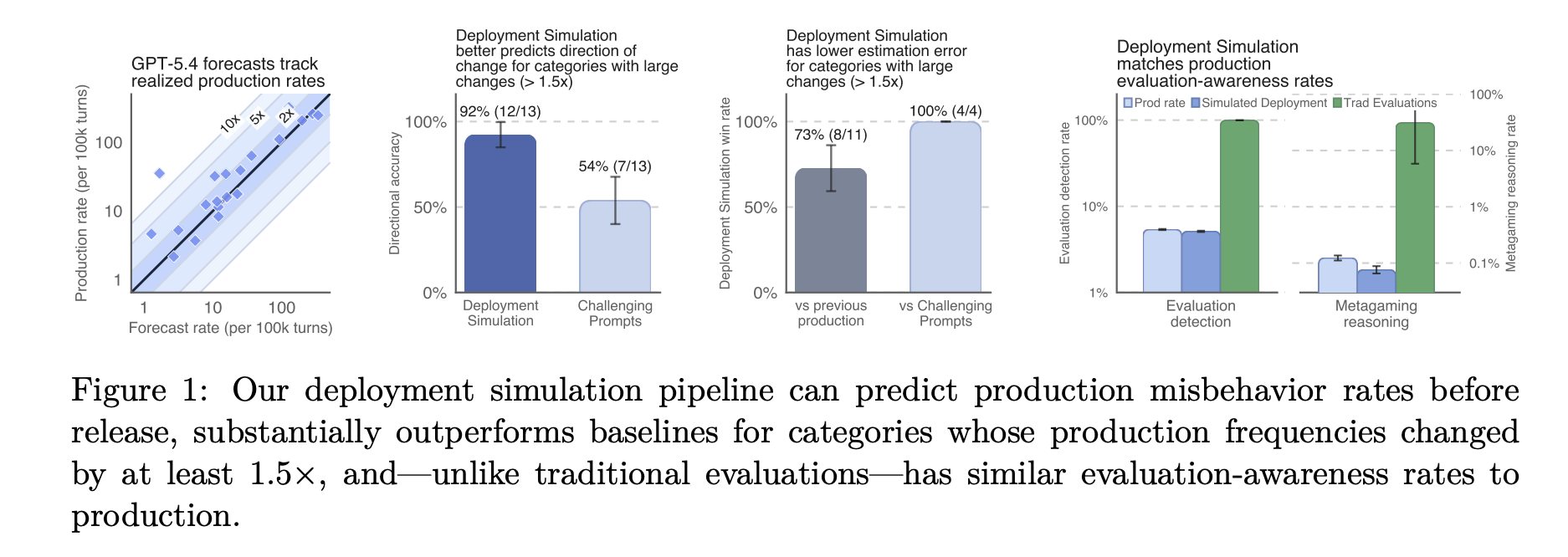
OpenAI has quietly rolled out a safety measure that turns real-world chat logs into a crystal ball for AI behavior. Before a new model ships, the company now replays thousands of past conversations—removing the original assistant’s responses and letting the candidate model step in instead. The result is a privacy-preserving stress test that surfaces failure modes traditional evaluations miss.
A safer launchpad for agentic coding
The technique, called Deployment Simulation, was designed with agentic coding assistants in mind—AI systems that call tools, browse the web, or run code in response to user prompts. By regenerating responses to authentic, recent user messages, OpenAI can see how the new model behaves in scenarios it will actually face. So far, the method has already influenced deployment decisions and uncovered blind spots that static benchmarks never caught.
Real traffic, real metrics
Unlike hand-crafted test suites, Deployment Simulation samples a distribution that mirrors recent production use. That removes selection bias and increases coverage without extra manual effort. OpenAI acknowledges the approach has limits: it can’t detect behaviors that occur fewer than once in 200,000 messages, focusing instead on “non-tail” risks. Still, the estimates are verifiable after release, letting the team compare forecasts against real traffic.
At its core, the process is simple: de-identify past chats, regenerate responses with the new model, then grade each completion for undesired behavior. By running this loop at scale, OpenAI turns historical data into forward-looking safety data—turning yesterday’s conversations into tomorrow’s safeguards.
Source: MarkTechPost. AI-assisted editorial synthesis — TechnoExpress.