

Anthropic’s Sonnet 5 Arrives: Smarter Coding, Sharper Pricing
Anthropic has rolled out Claude Sonnet 5, positioning it as the company’s most capable mid-tier model yet. Designed for extended autonomous tasks, it can plan, navigate browsers and terminals, and self-correct across long workflows. Available today as the default model for Free and Pro users, Sonnet 5 also reaches Max, Team, and Enterprise plans, plus the Claude Code and Claude Platform environments.
A step up in agentic reliability
Where earlier models struggled to maintain context over multi-step tasks, Sonnet 5 emphasizes “agentic reliability”—the ability to stay on course even when tool calls fail or conditions change. Anthropic frames this as a core upgrade rather than a single benchmark leap. In practice, that means fewer dropped contexts, more consistent self-correction, and steadier behavior during long sessions inside tools like Claude Code or Cowork.
Stronger benchmarks, gentler pricing
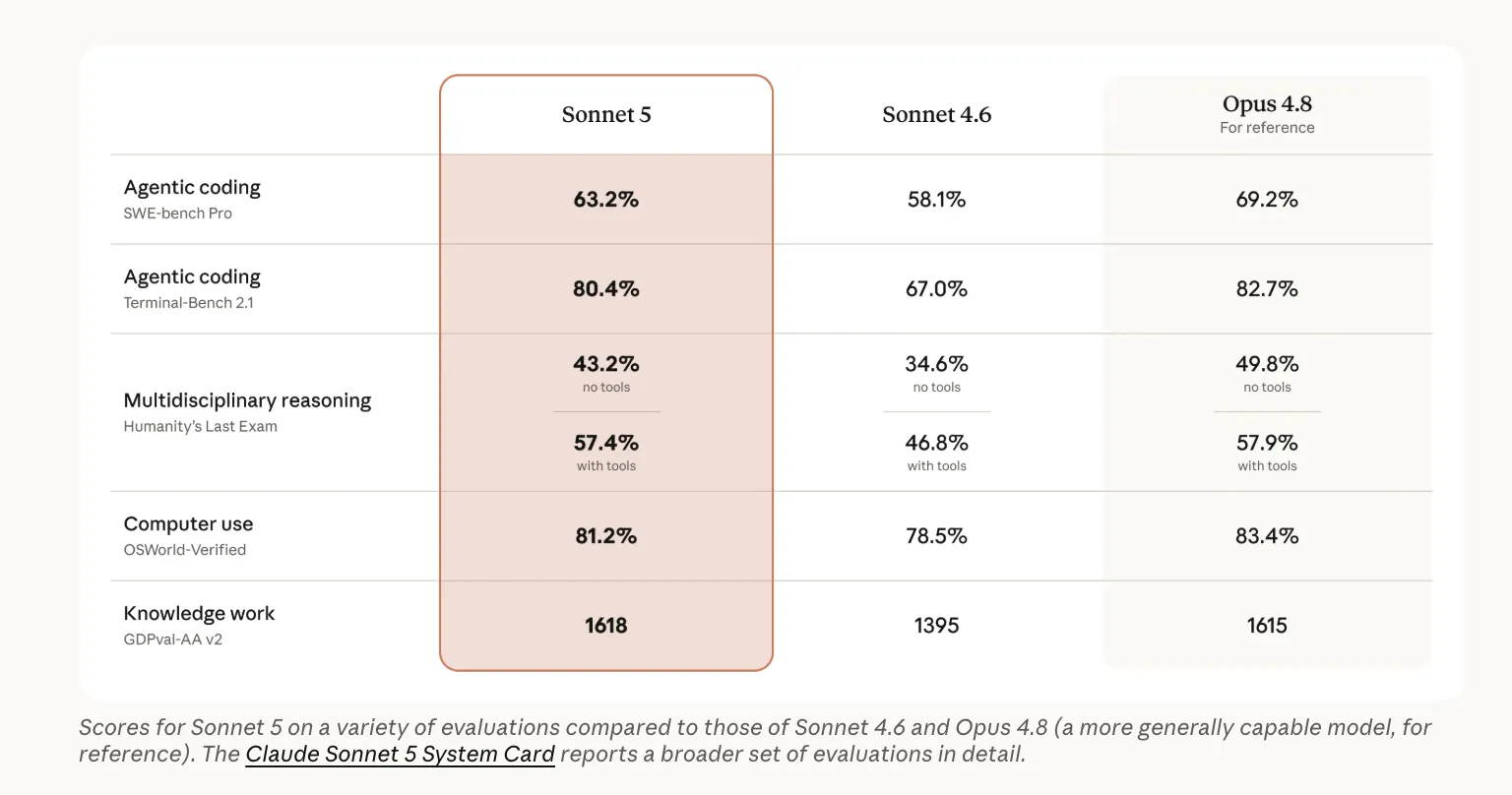
Across published agentic-coding tests, Sonnet 5 outpaces its predecessor Sonnet 4.6 in every category. On SWE-bench Pro it scores 63.2%, compared with 58.1% for Sonnet 4.6 and 69.2% for the flagship Opus 4.8. Computer-use tasks (OSWorld-Verified) see Sonnet 5 at 81.2% versus 78.5%, and Terminal-Bench 2.1 jumps to 80.4% from 67.0%. On Humanity’s Last Exam with tools, Sonnet 5 reaches 57.4%, nearly matching Opus 4.8’s 57.9%. In knowledge-work evaluations (GDPval-AA v2), it edges Opus 4.8 by a narrow margin.
API pricing for Sonnet 5 is set at an introductory $2/$10 per million tokens (input/output) through August 31, rising to $3/$15 thereafter. Opus 4.8 remains $5/$25. For low- to medium-effort tasks, Sonnet 5 offers the best value, but at extra-high effort levels its token usage can make it pricier than Opus 4.8 for similar quality.
Tokenizer tweaks and trade-offs
Sonnet 5 adopts the updated tokenizer introduced with Opus 4.7, mapping the same text to roughly 1.0–1.35 times more tokens. That increases per-task token counts and thus costs if effort levels are high. Anthropic also stresses that Sonnet 5’s cyber capabilities are deliberately constrained for safety, positioning Opus 4.8 as the choice for accuracy-critical work.
Source: MarkTechPost. AI-assisted editorial synthesis — TechnoExpress.