

Affrontement des techniques de compression du cache KV : TurboQuant, OSCAR et EpiCache
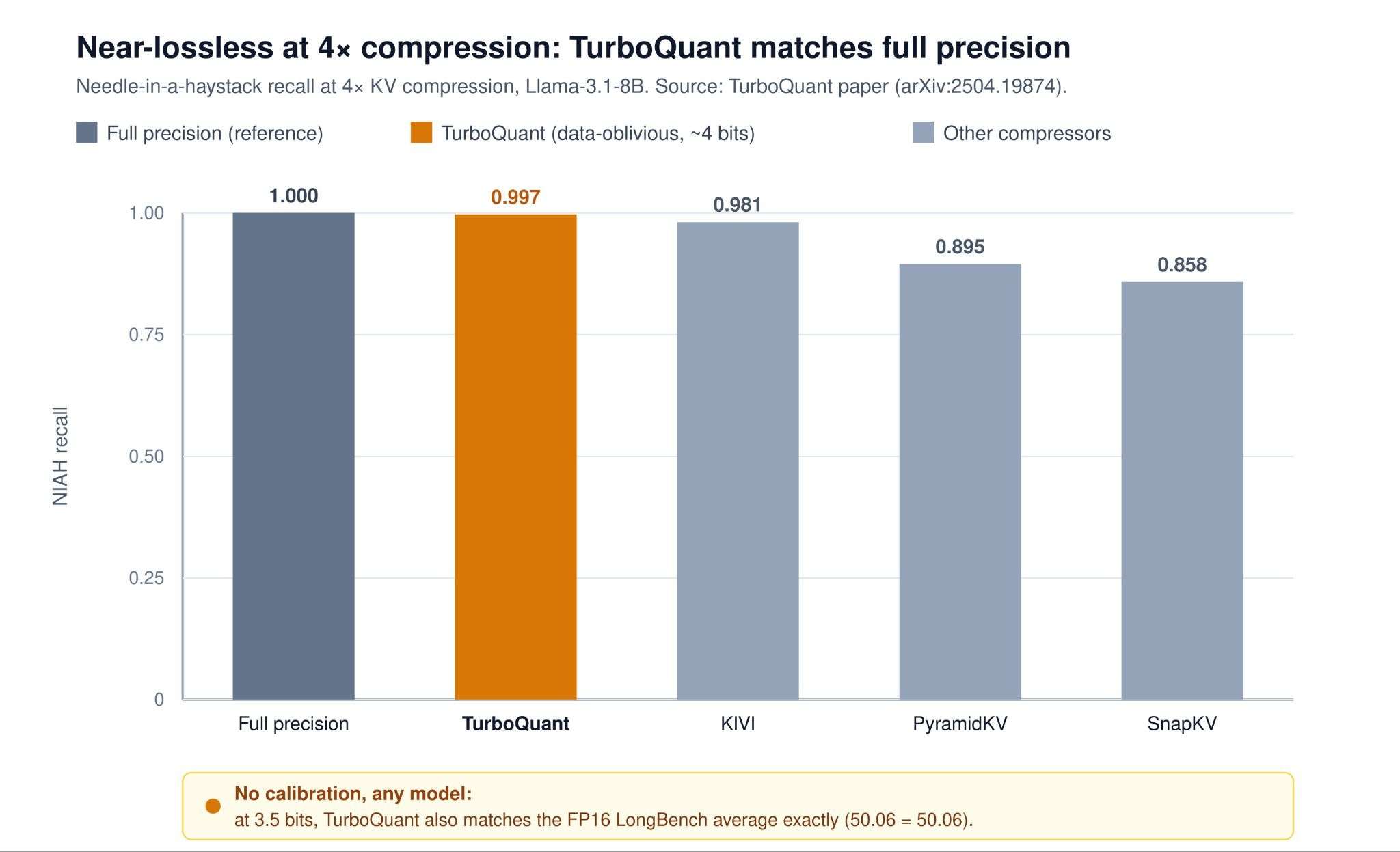
Les grands modèles de langage à long contexte se heurtent à une limite—notamment pas à cause de leurs poids massifs, mais en raison du cache KV gourmand en mémoire qui s’accroît avec chaque token. Pour des modèles comme Llama-3.1-70B, ce cache peut gonfler à plus de 300 Go à un million de tokens, dépassant largement le modèle lui-même. Le réduire est désormais le moyen le plus efficace pour diminuer à la fois les coûts et la latence de décodage.
Briser le goulot d’étranglement des valeurs aberrantes
Les approches actuelles relèvent ce défi par des méthodes variées. TurboQuant, développé par Google et NYU, emprunte une voie indépendante des données : il utilise des rotations aléatoires et une quantification scalaire pour neutraliser les canaux aberrants sans étalonnage. Ses garanties théoriques assurent une performance quasi sans perte jusqu’à 3,5 bits par canal, le rendant agnostique au modèle et idéal pour les bases de données vectorielles. OSCAR, de Together AI, se concentre quant à lui sur le déploiement pratique, combinant un regroupement conscient de l’attention avec une quantification sur 2 bits pour préserver la précision tout en réduisant la taille du cache. Apple, avec EpiCache, comble une lacune que les deux autres ne couvrent pas : il comprime le cache en exploitant le partage architectural, offrant une voie alternative vers l’efficacité.
De la théorie à la pratique
La force de TurboQuant réside dans ses fondements théoriques—des limites prouvables de distorsion et l’absence d’étalonnage nécessaire—mais ses gains réels se révèlent surtout dans la plage de 3 à 4 bits. OSCAR, à l’inverse, est conçu pour une utilisation concrète, équilibrant compression et préparation au déploiement. EpiCache adopte une approche distincte, ciblant les scénarios où les optimisations architecturales peuvent atténuer davantage la pression sur la mémoire. Ensemble, ces méthodes illustrent une tendance croissante : à mesure que les modèles s’orientent vers des contextes à millions de tokens, la gestion efficace du cache KV devient aussi cruciale que l’architecture du modèle lui-même.
Source : MarkTechPost. Synthèse éditoriale assistée par IA — TechnoExpress.