

Baidu’s Unlimited OCR delivers seamless long-document parsing with flat memory
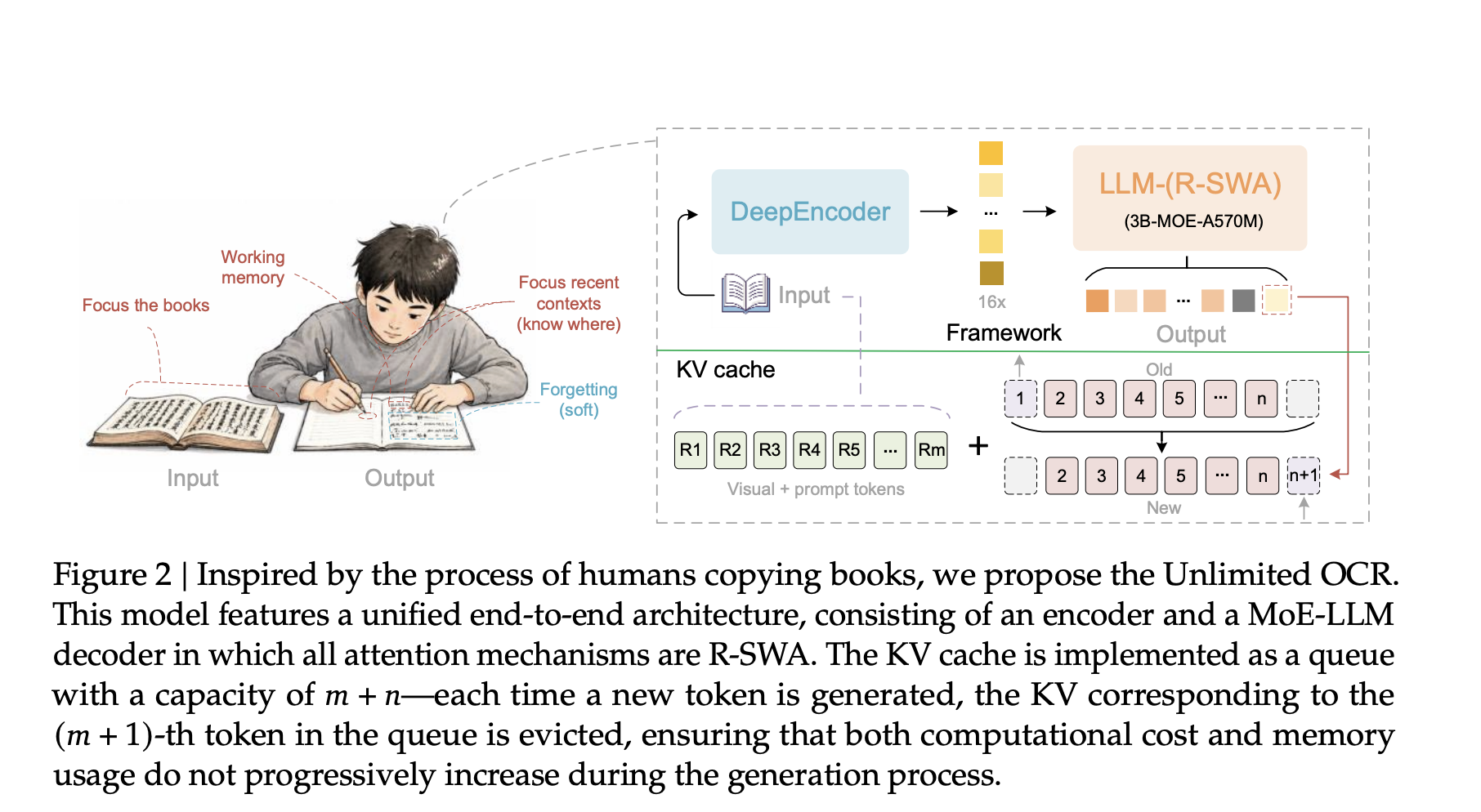
Baidu has unveiled Unlimited OCR, a 3-billion-parameter model that parses dozens of pages in a single pass without the usual memory bloat. By replacing standard decoder attention with Reference Sliding Window Attention, the system keeps its key-value cache constant regardless of output length, slashing latency and memory overhead while maintaining high accuracy.
Breaking the length–memory link
Traditional OCR pipelines slow down as documents grow because each new token inflates the KV cache; memory and compute rise in lockstep with output size. Unlimited OCR sidesteps this by letting every generated token attend only to a fixed set of reference tokens and the most recent 128 output tokens. The cache size therefore caps out at a small constant, yielding a near-constant per-step latency even when transcribing hundreds of pages.
A lean 500 M active model built on DeepSeek OCR
Unlimited OCR inherits the DeepSeek OCR architecture but folds in a Mixture-of-Experts decoder that exposes only 500 million parameters at inference. A dual-stage DeepEncoder first compresses 1024×1024 PDF images into just 256 visual tokens, reducing the prefill load. The model then runs in either “Base” mode for multi-page work or “Gundam” mode for single pages with dynamic resolution, offering practical flexibility without sacrificing detail.
Benchmark gains without retraining from scratch
On OmniDocBench v1.5, Unlimited OCR scores 93.23 points, beating the DeepSeek OCR baseline by 6.22 points. Rather than starting from scratch, Baidu continued training the existing model, demonstrating that targeted architectural tweaks can yield measurable improvements without the cost of full retraining. The result is a system that handles ever-longer documents efficiently while preserving accuracy—an important step for real-world OCR deployments.
Source: MarkTechPost. AI-assisted editorial synthesis — TechnoExpress.