

Le modèle OCR illimité de Baidu analyse des documents longs sans alourdir la mémoire
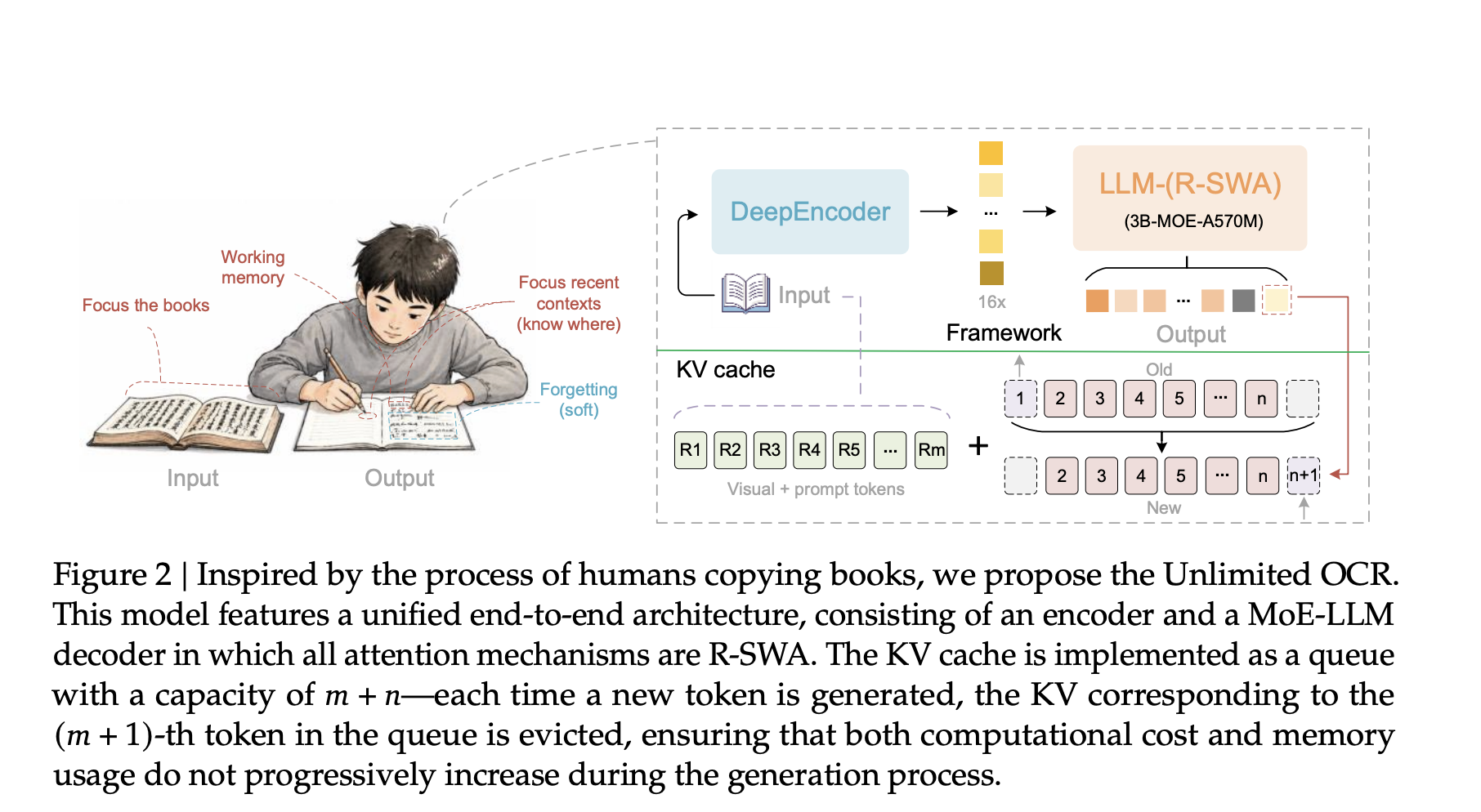
Baidu a dévoilé Unlimited OCR, un modèle de 3 milliards de paramètres capable d’analyser des dizaines de pages en une seule passe, sans l’encombrement mémoire habituel. En remplaçant l’attention standard du décodeur par une attention à fenêtre glissante de référence, le système maintient sa mémoire clé-valeur constante, quelle que soit la longueur de sortie. Cela réduit considérablement la latence et les ressources mémoire tout en conservant une haute précision.
Rompre le lien entre longueur et mémoire
Les pipelines OCR traditionnels ralentissent à mesure que les documents s’allongent, car chaque nouveau jeton gonfle le cache KV : mémoire et calcul augmentent proportionnellement à la taille de la sortie. Unlimited OCR contourne ce problème en permettant à chaque jeton généré de ne s’attacher qu’à un ensemble fixe de jetons de référence et aux 128 jetons de sortie les plus récents. La taille du cache est ainsi plafonnée à une petite constante, offrant une latence quasi constante par étape, même lors de la transcription de centaines de pages.
Un modèle léger de 500 millions de paramètres actifs, inspiré de DeepSeek OCR
Unlimited OCR s’appuie sur l’architecture de DeepSeek OCR, mais intègre un décodeur à mélange d’experts qui n’expose que 500 millions de paramètres en inférence. Un DeepEncoder en deux étapes compresse d’abord les images PDF 1024×1024 en seulement 256 jetons visuels, réduisant la charge de préremplissage. Le modèle fonctionne ensuite en mode « Base » pour les travaux multi-pages ou en mode « Gundam » pour les pages uniques avec résolution dynamique, offrant une flexibilité pratique sans sacrifier les détails.
Des performances supérieures sans réentraînement complet
Sur OmniDocBench v1.5, Unlimited OCR obtient un score de 93,23 points, dépassant la référence DeepSeek OCR de 6,22 points. Plutôt que de partir de zéro, Baidu a poursuivi l’entraînement du modèle existant, prouvant que des ajustements architecturaux ciblés suffisent pour améliorer les performances sans le coût d’un réentraînement complet. Le résultat est un système capable de traiter des documents de plus en plus longs de manière efficace, tout en préservant la précision – une avancée majeure pour les déploiements OCR en conditions réelles.
Source : MarkTechPost. Synthèse éditoriale assistée par IA — TechnoExpress.