

NVIDIA’s SpatialClaw rethinks AI spatial reasoning without extra training
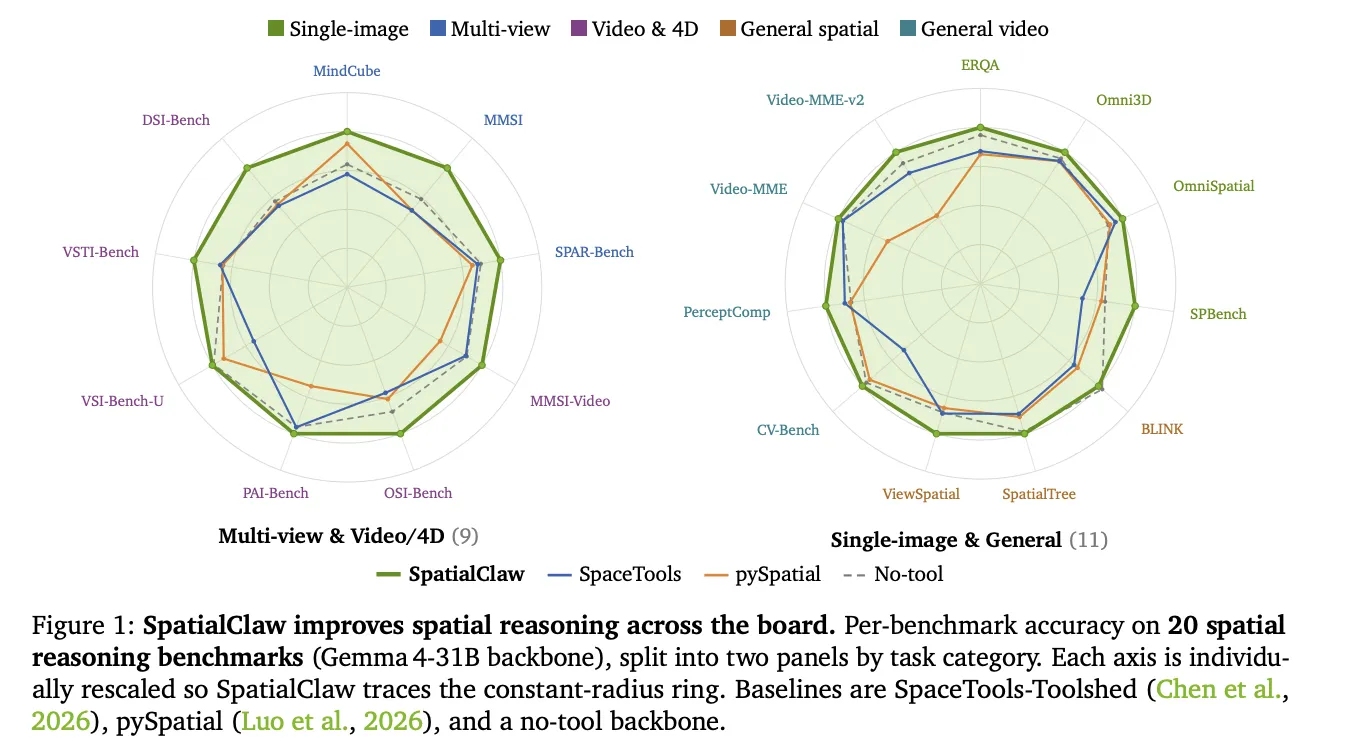
NVIDIA Research has unveiled SpatialClaw, a training-free framework that turns code into the action interface for spatial reasoning in vision-language models. Instead of fine-tuning weights, it lets an AI agent dynamically compose perception tools through Python, improving 3D object relations and movement judgments across 20 benchmarks with an average accuracy of 59.9%.
Rethinking the action bottleneck
Traditional spatial agents rely on fixed JSON schemas or single-pass scripts, which can lock in flawed assumptions before seeing intermediate results. SpatialClaw treats code as a live workspace: it calls tools like SAM 3 and Depth Anything 3, inspects their outputs, and revises its approach on the fly. In a test measuring the distance between a heater and a door, the agent first used a centroid-based estimate, then switched to a KDTree query when it detected the need for a true closest-point calculation—submitting 0.9439 m against a 0.9 m ground truth.
Performance across the board
On 20 benchmarks spanning single-image, multi-view, general, video, and 4D understanding, SpatialClaw outperformed the no-tool baseline on all six backbones tested, from 26B to 397B parameters. When compared to structured tool-call and single-pass code interfaces under identical conditions, its code-driven approach delivered the largest gain (+6.5 points) over the baseline. Against prior spatial agents using the same Gemma4-31B backbone, the gap widened further, highlighting the interface’s role as a key lever for accuracy.
Source: MarkTechPost. AI-assisted editorial synthesis — TechnoExpress.