

SpatialClaw de NVIDIA repense le raisonnement spatial en IA sans entraînement supplémentai
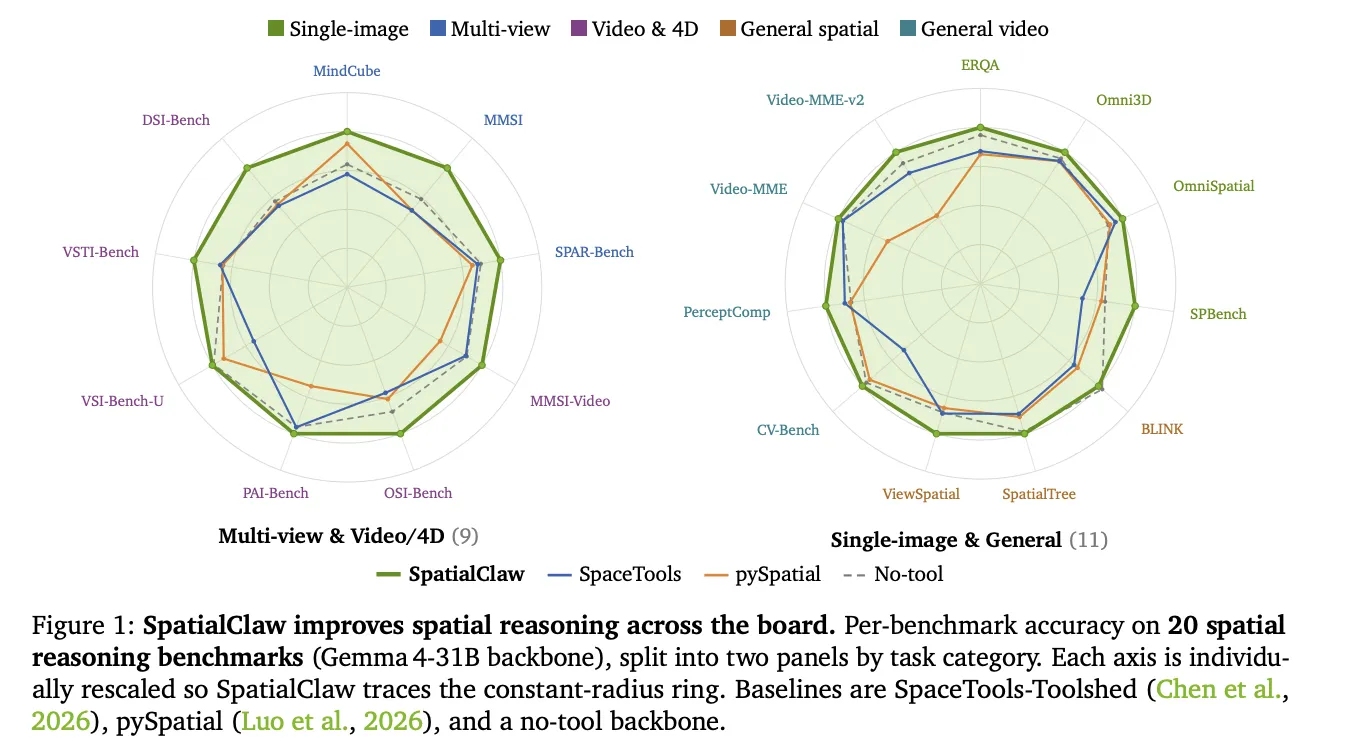
NVIDIA Research a dévoilé SpatialClaw, un cadre sans entraînement qui transforme le code en interface d’action pour le raisonnement spatial des modèles vision-langage. Au lieu d’ajuster les poids, il permet à un agent IA de composer dynamiquement des outils de perception via Python, améliorant les jugements sur les relations d’objets en 3D et leurs mouvements sur 20 références, avec une précision moyenne de 59,9 %.
Repenser le goulot d’étranglement des actions
Les agents spatiaux traditionnels s’appuient sur des schémas JSON fixes ou des scripts à passage unique, ce qui peut figer des hypothèses erronées avant même d’obtenir des résultats intermédiaires. SpatialClaw considère le code comme un espace de travail interactif : il appelle des outils comme SAM 3 et Depth Anything 3, examine leurs sorties et ajuste sa méthode en temps réel. Lors d’un test mesurant la distance entre un radiateur et une porte, l’agent a d’abord utilisé une estimation basée sur le centroïde, puis est passé à une requête KDTree en détectant la nécessité d’un calcul de point le plus proche – soumettant 0,9439 m face à une vérité terrain de 0,9 m.
Performances généralisées
Sur 20 références couvrant la compréhension d’images uniques, multi-vues, générale, vidéo et en 4D, SpatialClaw a surpassé la référence sans outil sur les six architectures testées, allant de 26 milliards à 397 milliards de paramètres. Comparé aux interfaces d’appel d’outils structurées et aux scripts à passage unique dans des conditions identiques, son approche par code a offert le gain le plus élevé (+6,5 points) par rapport à la référence. Face aux agents spatiaux antérieurs utilisant la même architecture Gemma4-31B, l’écart s’est encore creusé, soulignant le rôle de l’interface comme levier clé pour la précision.
Source : MarkTechPost. Synthèse éditoriale assistée par IA — TechnoExpress.