

MiniMax dévoile MSA : une attention éparse efficace pour les longs contextes
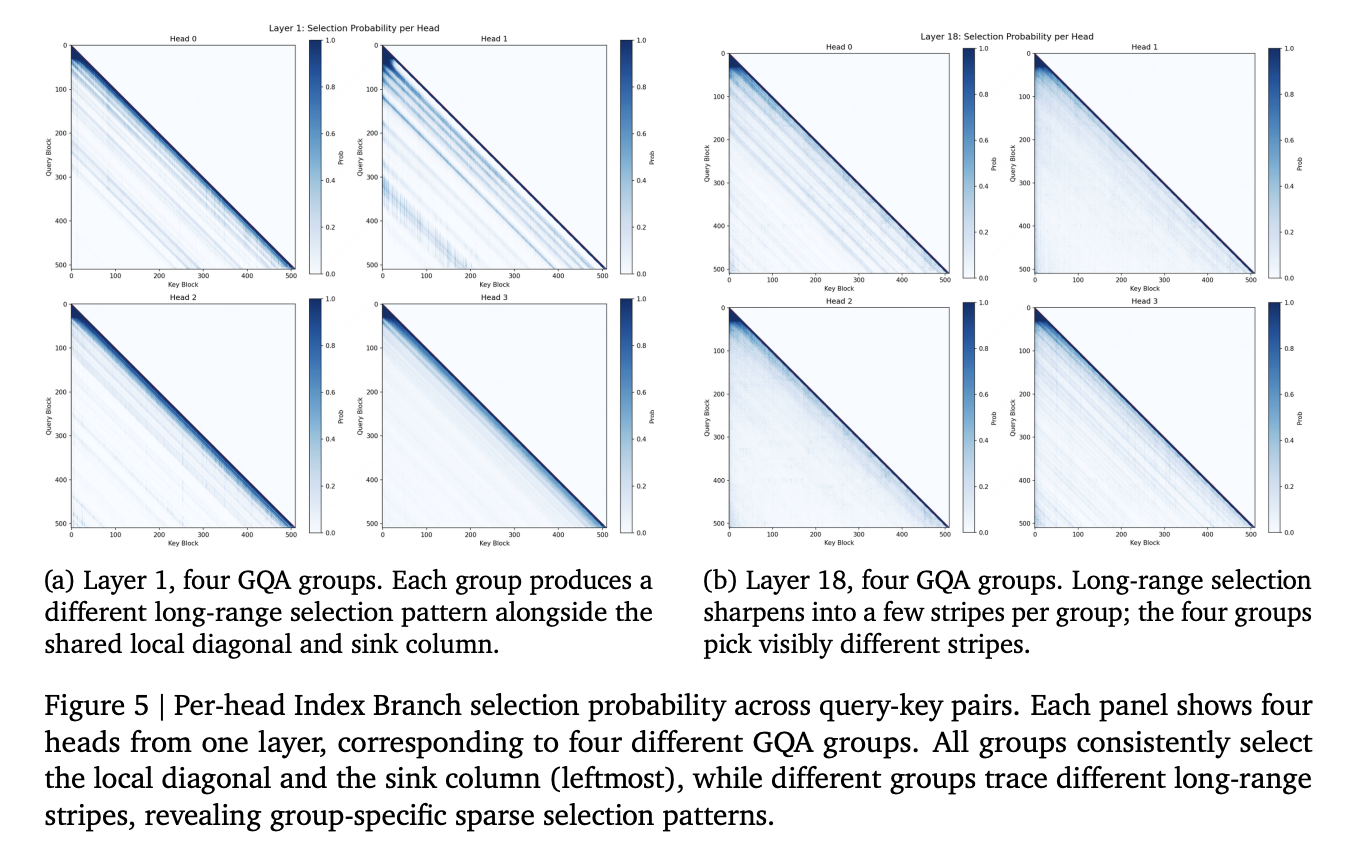
MiniMax a lancé MSA (MiniMax Sparse Attention), un mécanisme d'attention éparse innovant conçu pour résoudre les inefficacités de calcul de l'attention softmax classique dans les scénarios de long contexte. En s'attaquant au coût quadratique de l'attention sur des longueurs de jetons étendues, MSA permet un entraînement et une inférence plus rapides et évolutifs, avec des applications potentielles dans des tâches complexes comme le raisonnement multimodal et les dialogues prolongés. La méthode, basée sur Grouped Query Attention (GQA), a été testée dans un modèle MoE à 109 milliards de paramètres et open sourcée, accompagnée d'un modèle de production, MiniMax-M3.
Fonctionnement de MSA : une architecture à deux branches
MSA divise l'attention en deux étapes : une branche d'indexation et une branche principale. La branche d'indexation identifie les blocs clé-valeur que chaque requête doit consulter, tandis que la branche principale effectue une attention softmax exacte uniquement sur ces blocs sélectionnés. En opérant au niveau des blocs (taille par défaut : 128 jetons), MSA limite les jetons clé-valeur par requête à 2 049, réduisant drastiquement la charge de calcul. Cette approche évolue selon une complexité O(kBk) au lieu de O(N), devenant de plus en plus efficace à mesure que la longueur du contexte augmente.
Entraînement de MSA : surmonter les défis de la parcimonie
L'entraînement des modèles à attention éparse est complexe en raison de la sélection top-k non différentiable. MSA résout ce problème avec une perte d'alignement KL, qui ajuste la distribution de la branche d'indexation aux motifs d'attention de la branche principale. Des mesures de protection supplémentaires, comme le détachement des gradients pour isoler les projections d'indexation et le préchauffage de l'indexeur pour stabiliser l'entraînement, garantissent une robustesse accrue. Des études d'ablation ont affiné la conception en éliminant les composants redondants pour plus d'efficacité.
Implications pour les grands modèles
Les gains d'efficacité de MSA pourraient redéfinir la manière dont les grands modèles gèrent les tâches de long contexte, des chatbots à l'analyse de documents. En réduisant les coûts de calcul sans sacrifier la précision, MiniMax positionne MSA comme une innovation clé dans l'IA évolutive. Le noyau d'inférence open sourcé et le modèle de production suggèrent une adoption rapide en conditions réelles, potentiellement établissant un nouveau standard pour les mécanismes d'attention dans le secteur.
Source : MarkTechPost. Synthèse éditoriale assistée par IA — TechnoExpress.